
The Nationwide Inpatient Sample (NIS) is one of a family of databases and software tools developed as part of the Healthcare Cost and Utilization Project (HCUP), a Federal-State-Industry partnership sponsored by the Agency for Healthcare Research and Quality (AHRQ). The NIS is the largest nationwide all-payer hospital inpatient care database in the U.S. Each year the NIS contains data from approximately seven million hospital stays — all discharge data from nearly 1000 hospitals selected from HCUP State Inpatient Databases (SID) data, approximating a 20% stratified sample of U.S. community hospitals. The NIS team developed the NIS to provide analyses of hospital utilization, charges, and quality of care across the United States. The target universe includes all acute-care discharges from non-rehabilitation, community hospitals in the United States. There were 4,812 hospitals in the hospital universe in 2001. The 2001 NIS comprises all discharges from a sample of hospitals in this target universe.
This report describes the NIS sample and weights, summarizes the contents of the 2001 NIS, and discusses data analysis issues. Previous NIS releases covered 1988 through 2000. This document highlights cumulative information for all previous years to provide a longitudinal view of the database. The five new states in the 2001 NIS have enhanced the nationwide representation of the sample, making this the most comprehensive NIS to date.
The NIS sampling frame included all community, non-rehabilitation hospitals in the SID that could be matched to the corresponding American Hospital Association (AHA) Annual Survey data. Based on data from 33 states, there were 3,377 hospitals in the 2001 sampling frame, an 11% increase from the 2000 NIS. The NIS is a stratified probability sample of hospitals in the frame, with sampling probabilities calculated to select 20% of the universe contained in each stratum. The overall objective was to select a sample of hospitals representative of the target universe. With this objective in mind, NIS sampling strata were defined based on five hospital characteristics contained in the AHA hospital files.
Once the universe of hospitals was stratified, up to 20% of the total number of U.S. hospitals was randomly selected within each stratum. If a stratum contained too few frame hospitals, then all were selected for the NIS, subject to sampling restrictions specified by states. The resulting sample for 2001 included 986 hospitals, 20.5% of the total hospital universe of 4,812 hospitals.
Given the increase in the number of contributing states, the NIS team evaluated and revised the sampling and weighting strategy for 1998 and subsequent data years in order to best represent the U.S. This included changes to the definitions of the strata variables, the exclusion of rehabilitation hospitals from the NIS hospital universe, and a change to the calculation of hospital universe discharges for the weights. Also, beginning with the 1998 NIS sampling procedures, all frame hospitals within a stratum have an equal probability of selection for the sample, regardless of whether they had been in prior NIS samples. This deviates from the procedure used for earlier samples, which maximized the longitudinal component of the NIS series. A full description of the evaluation and revision of the NIS sampling strategy for 1998 and subsequent data years can be found in the special report on Changes in NIS Sampling and Weighting Strategy for 1998. This report is available on the 2001 NIS Documentation CD-ROM and on the HCUP User Support Website at www.hcup-us.ahrq.gov.
The 2001 NIS sampling frame included data provided by 33 HCUP State Partners. Over 90% of the hospital universe is included in the sampling frame for all but six of these states. Four State Partners — Hawaii, Minnesota, Missouri, and South Carolina — imposed sampling restrictions that reduced the number of state hospitals included in the frame to between 61 and 87 percent. (Restrictions from other states did not have an appreciable effect on the percentage of hospitals in the sampling frame.) One State Partner, Texas, supplied data from only 71% of the state´s hospitals because some Texas hospitals, mostly small rural hospitals, are exempt from statutory reporting requirements. We dropped 41 Michigan hospitals that did not report total charges from the sampling frame leaving 68% of Michigan hospitals in the frame.
While 20% of the hospitals from each region are selected for the NIS, the comprehensiveness of the sampling frame varies by region. In the Northeast, 93.6% of hospitals are included in the sampling frame, compared to 76.3% in the West; 64.2% in the Midwest, and 63.2% in the South. Because the NIS sampling frame has a disproportionate representation of the more populous states and includes hospitals with more annual discharges, its comprehensiveness in terms of discharges is higher. The states in the NIS sampling frame contain 97.7% of the population in the Northeast, 88.7% in the West, 81.0% in the South, and 70.8% in the Midwest. Overall, the sampling frame for the NIS comprises 70.2% of all U.S. hospitals and covers 83.6% of the U.S. population.
The final 2001 sample included 7,452,727 discharges from 986 hospitals selected from all 33 frame states. Hospitals were sampled throughout each region of the United States. In the Northeast and West, where a higher proportion of states are represented, relatively fewer hospitals are sampled from each state than in the South and Midwest, where the proportion of states in the NIS is lower. Since the original 1988 NIS, the size of the NIS has grown across several dimensions:
The additional states have enhanced the representation of the nationwide population. The 2001 NIS includes data from 33 states — five more states than the 2000 NIS and 25 more states than the original 1988 NIS. The three Midwestern states added to the 2001 NIS have substantially increased the percentage of the Midwestern population represented, from 45% in the 2000 NIS to 71% in the 2001 NIS.
Ideally, relationships among outcomes and their correlates estimated from the NIS should hold across all U.S. hospitals. However, when creating nationwide estimates, it is a good idea to check your estimates against other data sources, if available. For example, the National Hospital Discharge Survey (http://www.cdc.gov/nchs/products/pubs/pubd/series/sr13/ser13.htm) can provide benchmarks against which to check your national estimates for hospitalizations with more than 5000 cases.
The NIS Comparison Report provides an assessment of the accuracy of NIS estimates. The most recent report is provided on the NIS Documentation CD-ROM and usually compares the previous year´s NIS with other data sources. The updated report for the current NIS will be available on the HCUP User Support Website (www.hcup-us.ahrq.gov) later in the year of data release (e.g., the 2001 NIS Comparison Report will be available in fall of 2003).
Two nonoverlapping 10% subsamples of discharges were drawn from the NIS file for several reasons pertaining to data analysis. One reason for creating the subsamples was to reduce processing costs for selected studies that will not require the entire NIS. Another reason is that the two subsamples may be used to validate models and obtain unbiased estimates of standard errors. The subsamples were selected by drawing every tenth discharge, starting with two different randomly selected starting points. Having a different starting point for each of the two subsamples guaranteed that the resulting subsamples would not overlap.
It is necessary to incorporate sample weights to obtain nationwide estimates. Therefore, sample weights were developed separately for hospital- and discharge-level analyses. Within a stratum, each NIS sample hospital's universe weight is equal to the number of universe hospitals it represents during the year. Since 20% of the AHA universe hospitals in each stratum are sampled when possible, the hospital weights (HOSPWT) are usually around five. The calculations for discharge-level sampling weights (DISCWT) are similar to the calculations of hospital-level sampling weights. In the 10% subsamples, each discharge has a 10% chance of being drawn. Therefore, the discharge weights (DISCWT10) are multiplied by 10 for each of the subsamples. Because the 10% subsamples are based on a sampling of discharges, each hospital is represented in the subsamples, thus no adjustment is required for the hospital weight when using the subsamples.
To produce nationwide estimates, the discharge weights should be used to extrapolate sampled discharges in the Core file to the discharges from all U.S. community, non-rehabilitation hospitals. For the 2000 NIS, DISCWT should be used to create nationwide estimates for all analyses except those that involve total charges, and DISCWTCHARGE should be used to create nationwide estimates of total charges. For all other years of the NIS, including the 2001 NIS, DISCWTCHARGE is not required, and DISCWT (DISCWT_U prior to the 1998 NIS) should be used to create all estimates. For a 10% subsample file, use the corresponding subsample discharge weight, DISCWT10 (D10CWT_U prior to the 1998 NIS) or DISCWTCHARGE10.
Missing Values
Missing data values compromise the quality of estimates. If the outcome for discharges with missing values is different from the outcome for discharges with valid values, then sample estimates for that outcome will be biased and will not accurately represent the discharge population. Also, when estimating totals for non-negative variables with missing values, sums would tend to be underestimated because the cases with missing values would be omitted from the calculations. There are several techniques available to help overcome this bias. One strategy is to use imputation to replace missing values with acceptable values. Another strategy is to use sample weight adjustments to compensate for missing values. Such data preparation and adjustment is outside the scope of this report. However, if necessary, it should be done before analyzing data with statistical procedures.
Variance Calculations
It may be important for researchers to calculate a measure of precision for some estimates based on the NIS sample data. Variance estimates must take into account both the sampling design and the form of the statistic. Standard formulas for a stratified, single-stage cluster sample without replacement may be used to calculate statistics and their variances in most applications.
The NIS database includes a Hospital Weights file with variables required by statistical software to calculate finite population statistics. In addition to the sample weights described earlier, hospital identifiers (Primary Sampling Units or PSUs), stratification variables, and stratum-specific totals for the numbers of discharges and hospitals are included so that finite-population corrections (FPCs) can be applied to variance estimates. Examples of the use of SAS, SUDAAN and STATA to calculate variances in the NIS are presented in the special report: Calculating Nationwide Inpatient Sample Variances, 2001. This report is available on the 2001 NIS Documentation CD-ROM and on the HCUP User Support Website at www.hcup-us.ahrq.gov.
Longitudinal Analyses
All frame hospitals within a stratum have an equal probability of selection for the sample, regardless of whether they have been in prior NIS samples. This deviates from the procedure used for earlier samples, prior to data year 1998, which maximized the longitudinal component of the NIS series. Hospitals that continue in the NIS for multiple consecutive years are a subset of the hospitals in the NIS for any one of those years. Consequently, longitudinal analyses of hospital-level outcomes may be biased if they are based on any subset of NIS hospitals limited to continuous NIS membership. The analyses may be more efficient (e.g., produce more precise estimates) if they account for the potential correlation between repeated measures on the same hospital over time.
The Nationwide Inpatient Sample (NIS) is one of a family of databases and software tools developed as part of the Healthcare Cost and Utilization Project (HCUP), a Federal-State-Industry partnership sponsored by the Agency for Healthcare Research and Quality (AHRQ). The NIS is the largest nationwide all-payer hospital inpatient care database in the U.S. Each year the NIS contains data from approximately seven million hospital stays — all discharge data from nearly 1000 hospitals selected from HCUP State Inpatient Databases (SID) data, approximating a 20% stratified sample of U.S. non-rehabilitation, community hospitals. The target universe includes all acute-care discharges from non-rehabilitation, community hospitals in the United States. The NIS comprises all discharges from a sample of hospitals in this target universe.
The HCUP NIS team developed the NIS to facilitate analyses of hospital utilization, charges, and quality of care across the United States. Potential research issues focus on both discharge- and hospital-level outcomes. Discharge outcomes of interest include trends in inpatient treatments with respect to:
Hospital outcomes of interest include:
These and other outcomes are of interest for the nation as a whole and for policy-relevant inpatient subgroups defined by geographic regions, patient demographics, hospital characteristics, physician characteristics, and pay sources.
This report describes the NIS sample and weights, summarizes the contents of the 2001 NIS, and discusses data analysis issues. The 2001 NIS includes data for calendar year 2001. Previous NIS releases covered 1988 through 2000. This document highlights cumulative information for all previous years to provide a longitudinal view of the database.
Table 1 displays the number of states, hospitals, and discharges in each year and reveals the increase in the number of participating states over time. The five new states in the 2001 NIS have enhanced the nationwide representation of the sample, making this the most comprehensive NIS to date.
| Calendar Year | States in the Frame |
Number of States | Sample Hospitals | Sample Discharges (Millions) |
|---|---|---|---|---|
| 1988–1992 | Arizona, California, Colorado, Florida, Iowa, Illinois, Massachusetts, New Jersey, Pennsylvania, Washington, and Wisconsin | 8–11 | 758–875 | 5.2–6.2 |
| 1993 | Add Connecticut, Kansas, Maryland, New York, Oregon, and South Carolina | 17 | 913 | 6.5 |
| 1994 | No new additions | 17 | 904 | 6.4 |
| 1995 | Add Missouri and Tennessee | 19 | 938 | 6.7 |
| 1996 | No new additions | 19 | 906 | 6.5 |
| 1997 | Add Georgia, Hawaii, and Utah | 22 | 1012 | 7.1 |
| 1998 | No new additions | 22 | 984 | 6.8 |
| 1999 | Add Maine and Virginia | 24 | 984 | 7.2 |
| 2000 | Add Kentucky, North Carolina, Texas, and West Virginia | 28 | 994 | 7.5 |
| 2001 | Add Michigan, Minnesota, Nebraska, Rhode Island, and Vermont | 33 | 986 | 7.5 |
The hospital universe is defined as all hospitals located in the U.S. that were open during any part of the calendar year and that were designated as community hospitals in the American Hospital Association (AHA) Annual Survey. The AHA defines community hospitals as follows: "All nonfederal short-term general and other specialty hospitals, excluding hospital units of institutions." Consequently, Veterans Hospitals and other federal facilities (Department of Defense and Indian Health Service) are excluded. Beginning with the 1998 NIS, community, rehabilitation hospitals were excluded from the universe because the type of care provided and the characteristics of the discharges from these facilities were markedly different from other short-term hospitals. Figure 1 displays the number of universe hospitals for each year based on the AHA Annual Survey; a steady decline in the number of hospitals is evident.
Figure 1: Hospital Universe, by Year1 (text version)
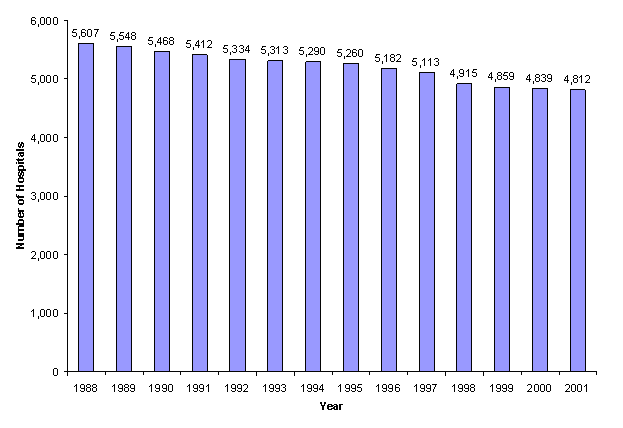
All U.S. hospital entities that were designated community hospitals in the AHA hospital file, except rehabilitation hospitals, were included in the hospital universe. Therefore, when two or more community hospitals merged to create a new community hospital, the original hospitals and the newly formed hospital were all considered separate hospital entities in the universe during the year they merged. Likewise, if a community hospital split, the original hospital and all newly created community hospitals were separate entities in the universe during the year they split. Finally, community hospitals that closed during a year were included as long as they were in operation during some part of the calendar year.
Given the increase in the number of contributing states, the NIS team evaluated and revised the sampling and weighting strategy for 1998 and subsequent data years in order to best represent the U.S. This included changes to the definitions of the strata variables, the exclusion of rehabilitation hospitals from the NIS hospital universe, and a change to the calculation of hospital universe discharges for the weights. A full description of this process can be found in the special report on Changes in NIS Sampling and Weighting Strategy for 1998. This report is available on the 2001 NIS Documentation CD-ROM and on the HCUP User Support Website at www.hcup-us.ahrq.gov. A description of the sampling procedures and definitions of strata variables used from 1988 through 1997 can be found in the special report: Design of the HCUP Nationwide Inpatient Sample, 1997. This report is available on the 1997 NIS Documentation CD-ROM and on the HCUP User Support Website.
The NIS sampling strata were defined based on five hospital characteristics contained in the AHA hospital files. Beginning with the 1998 NIS, the stratification variables were defined as follows:
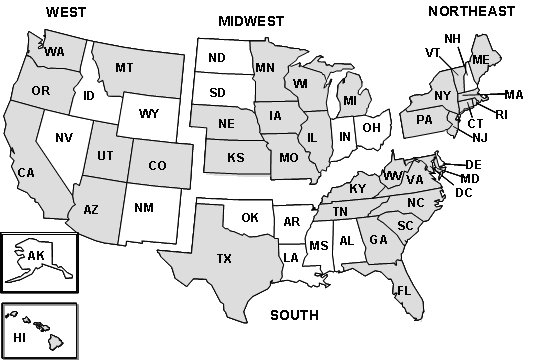
| Region | States |
|---|---|
| 1: Northeast | Connecticut , Maine, Massachusetts, New Hampshire, New Jersey, New York, Pennsylvania, Rhode Island, Vermont |
| 2: Midwest | Illinois, Indiana, Iowa, Kansas, Michigan, Minnesota, Missouri, Nebraska, North Dakota, Ohio, South Dakota, Wisconsin |
| 3: South | Alabama, Arkansas, Delaware, District of Columbia, Florida, Georgia, Kentucky, Louisiana, Maryland, Mississippi, North Carolina, Oklahoma, South Carolina, Tennessee, Texas, Virginia, West Virginia |
| 4: West | Alaska, Arizona, California, Colorado, Hawaii, Idaho, Montana, Nevada, New Mexico, Oregon, Utah, Washington, Wyoming |
The bed size cutoff points were chosen so that approximately one-third of the hospitals in a given region, location, and teaching status combination would fall within each bed size category (small, medium or large). Different cutoff points for rural, urban nonteaching, and urban teaching hospitals were used because hospitals in those categories tend to be small, medium, and large, respectively. For example, a medium-sized teaching hospital would be considered a rather large rural hospital. Further, the size distribution is different among regions for each of the urban/teaching categories. For example, teaching hospitals tend to be smaller in the West than they are in the South. Using differing cutoff points in this manner avoids strata containing small numbers of hospitals.
Rural hospitals were not split according to teaching status, because rural teaching hospitals were rare. For example, in 2001, rural teaching hospitals comprised less than 1% of the total hospital universe. The bed size categories were defined within location and teaching status because they would otherwise have been redundant. Rural hospitals tend to be small; urban non-teaching hospitals tend to be medium-sized; and urban teaching hospitals tend to be large. Yet it was important to recognize gradations of size within these types of hospitals. For example, in serving rural discharges, the role of “large” rural hospitals (particularly rural referral centers) often differs from the role of “small” rural hospitals.
To further ensure accurate geographic representation, implicit stratification variables included state and three-digit ZIP Code (the first three digits of the hospital's five-digit ZIP Code). Within each stratum, we sorted hospitals by three-digit ZIP Code prior to systematic random sampling.
| Location and Teaching Status | Hospital Bed Size | ||
|---|---|---|---|
| Small | Medium | Large | |
| NORTHEAST | |||
| Rural | 1-49 | 50-99 | 100+ |
| Urban, non-teaching | 1-124 | 125-199 | 200+ |
| Urban, teaching | 1-249 | 250-424 | 425+ |
| MIDWEST | |||
| Rural | 1-29 | 30-49 | 50+ |
| Urban, non-teaching | 1-74 | 75-174 | 175+ |
| Urban, teaching | 1-249 | 250-374 | 375+ |
| SOUTH | |||
| Rural | 1-39 | 40-74 | 75+ |
| Urban, non-teaching | 1-99 | 100-199 | 200+ |
| Urban, teaching | 1-249 | 250-449 | 450+ |
| WEST | |||
| Rural | 1-24 | 25-44 | 45+ |
| Urban, non-teaching | 1-99 | 100-174 | 175+ |
| Urban, teaching | 1-199 | 200-324 | 325+ |
The universe of hospitals was established as all community hospitals located in the U.S. with the exception, beginning in 1998, of rehabilitation hospitals. However, it was not feasible to obtain and process all-payer discharge data from a random sample of the entire universe of hospitals because it would have been too costly to obtain data from individual hospitals, and it would have been too burdensome to process each hospital's unique data structure.
Therefore, the NIS sampling frame was constructed from the subset of universe hospitals that released their discharge data for research use. When the 2001 sample was drawn, the Agency for Healthcare Research and Quality (AHRQ) had agreements with 33 HCUP State Partner organizations that maintain statewide, all-payer discharge data files to include their data in the HCUP databases. These HCUP State Partners were either state agencies or private data organizations (primarily state hospital associations). The number of State Partners contributing data to the NIS has increased over the years, as shown in Table 1. As a result, the number of hospitals included in the NIS sampling frame has also increased over the years, as shown in Figure 3.
The list of the entire frame of hospitals was composed of all AHA community hospitals in each of the frame states that could be matched to the discharge data provided to HCUP. If an AHA community hospital could not be matched to the discharge data provided by the data source, it was eliminated from the sampling frame (but not from the target universe).
Figure 3: NIS Hospital Sampling Frame, by Year (text version)
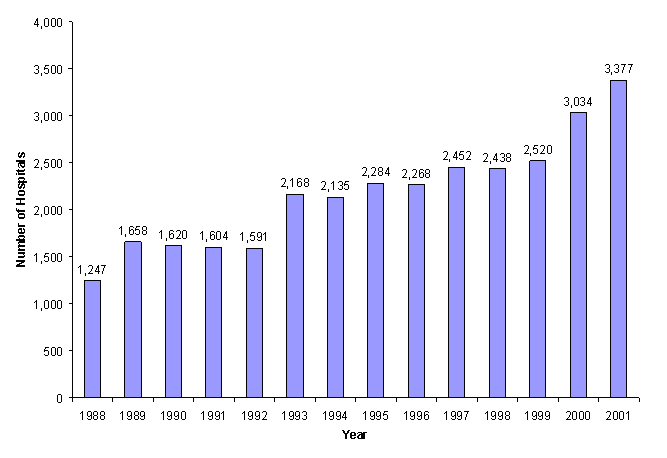
Figure 4 shows the number of hospitals in the universe, frame, and sample and the percentage of universe hospitals in the frame for each state in the sampling frame for 2001. The difference between the universe and the frame represents the difference in the number of community, non-rehabilitation hospitals in the 2001 AHA Annual Survey of Hospitals and the number of community, non-rehabilitation hospitals for which data were supplied to HCUP in all states except Georgia, Hawaii, Michigan, Missouri, Nebraska, and South Carolina.
The Georgia frame contains three hospitals less than the Georgia universe. Two hospitals were excluded because of sampling restrictions stipulated by Georgia, and one hospital identified in the AHA data was not included in the data supplied to HCUP.
The Hawaii frame contains seven hospitals less than the Hawaii universe. Four hospitals were excluded because of sampling restrictions stipulated by Hawaii, and three hospitals identified in AHA data were not included in the data supplied to HCUP.
The Michigan frame contains 45 hospitals less than the Michigan universe. Forty-one out of 137 Michigan frame hospitals did not report total charges. These hospitals are fairly evenly distributed by hospital type. There are no sampling strata in the state containing only hospitals without charges. The weakest sampling strata in the state are small teaching hospitals, with only 4 out of 10 hospitals with total charges and medium teaching hospitals, with only 3 out of 10 hospitals with total charges. The total charge data that is reported for Michigan is similar to total charge data reported by other Midwestern states. Thus, there does not seem to be an obvious bias in the type of cases for which charges are reported. The NIS team decided to drop the 41 hospitals that did not provide total charges from the frame. Our reasoning is that charges represent a critical outcome variable in the NIS and by dropping these hospitals, we avoid having to adjust the weights or create another weighting variable specifically for total charges as we did in the 2000 NIS to handle missing charges in Texas. The stratification and weighting scheme will adjust for the hospitals that are being dropped. In addition, four Michigan hospitals identified in AHA data were not included in the data supplied to HCUP.
The Missouri frame contains 46 hospitals less than the Missouri universe. Thirty-two hospitals were excluded because they signed releases for confidential use only, and fourteen hospitals identified in AHA data were not included in the data supplied to HCUP.
The Nebraska frame contains eleven hospitals less than the Nebraska universe. One hospital was excluded because of sampling restrictions stipulated by Nebraska. We dropped three additional hospitals from the sampling frame because they had incomplete data and were missing a high percentage of Medicare Discharges. Seven hospitals identified in AHA data were not included in the data supplied to HCUP.
The South Carolina frame contains eight hospitals less than the South Carolina universe. Six hospitals were excluded because of sampling restrictions stipulated by South Carolina, and two hospitals identified in AHA data were not included in the data supplied to HCUP.
Figure 4: Number of Hospitals in the 2002 Universe, Frame, and Sample for States in the Sampling Frame (text version)
Arizona – Missouri
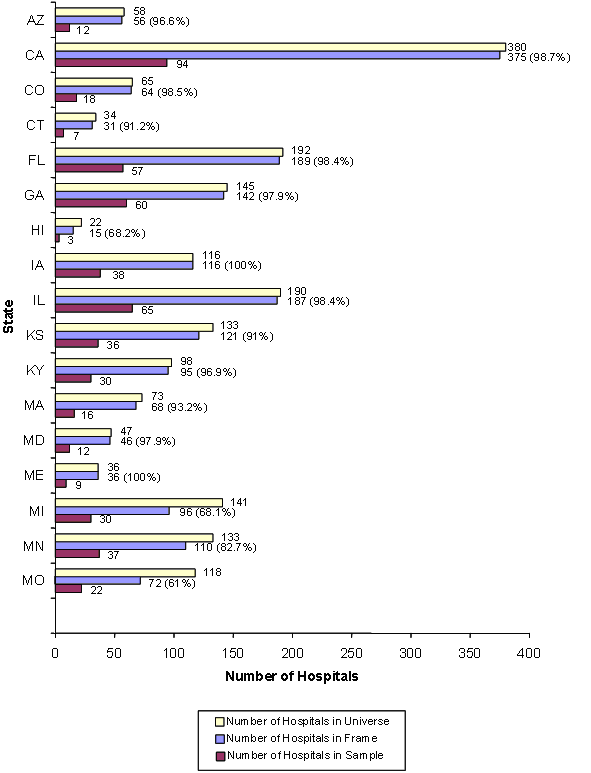
Figure 4: Number of Hospitals in the 2002 Universe, Frame, and Sample for States in the Sampling Frame (text version)
North Carolina – West Virginia
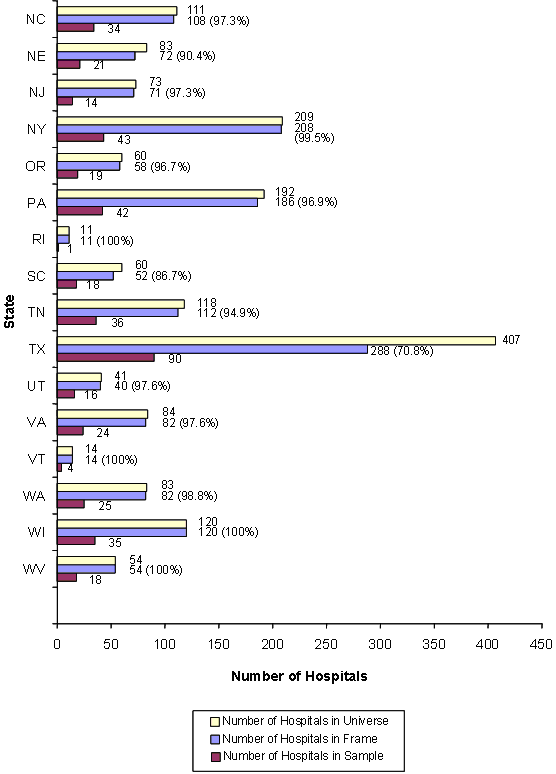
As evident in Figure 4, only 288 out of 407 (70.8%) of Texas community, non-rehabilitation hospitals supplied data to HCUP for 2001. Certain Texas state-licensed hospitals are exempt from statutory reporting requirements. Exempt hospitals include:
The Texas statute that exempts rural providers from being required to submit data defines a hospital as a rural provider if it:
These exemptions apply primarily to smaller rural public hospitals. As a result, smaller rural public hospitals are less likely to be included in the sampling frame than other Texas hospitals. While the number of hospitals omitted appears sizable, the hospitals available for the NIS include 94.5% of inpatient discharges from Texas universe hospitals.
The NIS is a stratified probability sample of hospitals in the frame, with sampling probabilities calculated to select 20% of the universe of U.S. community, non-rehabilitation hospitals contained in each stratum. This sample size was determined by AHRQ based on their experience with similar research databases. The overall design objective was to select a sample of hospitals that accurately represents the target universe, which includes hospitals outside the frame (i.e., having zero probability of selection). Moreover, this sample was to be geographically dispersed, yet drawn only from data supplied by HCUP Partners.
It should be possible, for example, to estimate DRG-specific average lengths of stay across all U.S. hospitals using weighted average lengths of stay, based on averages or regression coefficients calculated from the NIS. Ideally, relationships among outcomes and their correlates estimated from the NIS should hold across all U.S. hospitals. However, the 2001 NIS includes data from only 33 states. Therefore, it is a good idea to check your estimates against other data sources, if available. For example, the National Hospital Discharge Survey (http://www.cdc.gov/nchs/products/pubs/pubd/series/sr13/ser13.htm) can provide benchmarks against which to check your national estimates for hospitalizations with more than 5000 cases. The NIS Comparison Report provides an assessment of the accuracy of NIS estimates. The most recent report is provided on the NIS Documentation CD-ROM and usually compares the previous year´s NIS with other data sources. The updated report for the current NIS will be available on the HCUP User Support Website (www.hcup-us.ahrq.gov) later in the year of data release (e.g., the 2001 NIS Comparison Report will be available in fall of 2003).
The NIS team considered alternative stratified sampling allocation schemes. However, allocation proportional to the number of hospitals was preferred for several reasons:
Once the universe of hospitals was stratified, up to 20% of the total number of U.S. hospitals were randomly selected within each stratum. If too few frame hospitals were in the stratum, then all frame hospitals were selected for the NIS, subject to sampling restrictions specified by states. To simplify variance calculations, at least two hospitals were drawn from each stratum. If fewer than two frame hospitals were contained in a stratum, then that stratum was merged with an “adjacent” stratum containing hospitals with similar characteristics.
We drew a systematic random sample of hospitals from each stratum, after sorting hospitals by stratum, then by the three-digit ZIP Code (the first three digits of the hospital's five-digit ZIP Code) within each stratum, and then by a random number within each three-digit ZIP Code. These sorts ensured further geographic generalizability of hospitals within the frame states, as well as random ordering of hospitals within three-digit ZIP Codes.
Generally, three-digit ZIP Codes that are proximal in value are geographically near one another within a state. Furthermore, the U.S. Postal Service locates regional mail distribution centers at the three-digit level. Thus, the boundaries tend to be a compromise between geographic size and population size.
We drew two nonoverlapping 10% subsamples of discharges from the NIS file for each year. The subsamples were selected by drawing every tenth discharge starting with two different starting points (randomly selected between 1 and 10). Having a different starting point for each of the two subsamples guaranteed that they would not overlap. Discharges were sampled so that 10% of each hospital's discharges in each quarter were selected for each of the subsamples. The two samples can be combined to form a single, generalizable 20% subsample of discharges.
Beginning with the 1998 NIS sampling procedures, all frame hospitals within a stratum have an equal probability of selection for the sample, regardless of whether they had been in prior NIS samples. This deviates from the procedure used for earlier samples, which maximized the longitudinal component of the NIS series.
Further description of the sampling procedures for earlier releases of the NIS can be found in the special report: Design of the HCUP Nationwide Inpatient Sample, 1997. This report is available on the 1997 NIS Documentation CD-ROM and on the HCUP User Support Website at www.hcup-us.ahrq.gov. For a description of the development of the new sample design for 1998 and subsequent data years, see the special report: Changes in NIS Sampling and Weighting Strategy for 1998. This report is available on the 2001 NIS Documentation CD-ROM and on the HCUP User Support Website at www.hcup-us.ahrq.gov.
Beginning with the 1993 NIS, the NIS samples no longer contain zero-weight hospitals. For a description of zero-weight hospitals in the 1988-1992 samples, see the special report: Design of the HCUP Nationwide Inpatient Sample, Release 1. This report is available on the 1988-1992 NIS Documentation CD-ROM.
Figure 5 shows the numbers of hospitals sampled each year, and Figure 6 presents the numbers of discharges in each year of the NIS. For the 1988-1992 NIS, zero-weight hospitals were maintained to provide a longitudinal sample, so there are two figures for each of these years — one number for the regular NIS sample and another number for the total sample.
Figure 7 displays the weighted number of discharges sampled each year. Note that this number decreased from 35,408,207 in 1997 to 34,874,001 in 1998, a difference of 534,206 (1.5%). This slight decline is associated with two changes to the NIS design in 1998: the exclusion of community, rehabilitation hospitals from the hospital universe, and a change to the calculation of hospital universe discharges for the weights. Prior to 1998, we calculated discharges as the sum of total facility admissions (AHA data element ADMTOT), which includes long-term-care admissions, plus births (AHA data element BIRTHS) reported for each U.S. community hospital in the AHA Annual Survey. Beginning in 1998, we calculate discharges as the sum of hospital admissions (AHA data element ADMH) plus births for each U.S. community, non-rehabilitation hospital — a number that is more consistent with the number of discharges we receive from the state data sources — and we substitute total facility admissions if the number of hospital admissions is missing. Without these changes, the weighted number of discharges for 1998 would have been 35,622,743. The exclusion of community, rehabilitation hospitals reduced the number of universe hospitals by 177 and the number of weighted discharges by 214,490. The change in the calculation of discharges reduced the weighted number of discharges by 534,252.
Figure 5: Number of Hospitals Sampled, by Year (text version)
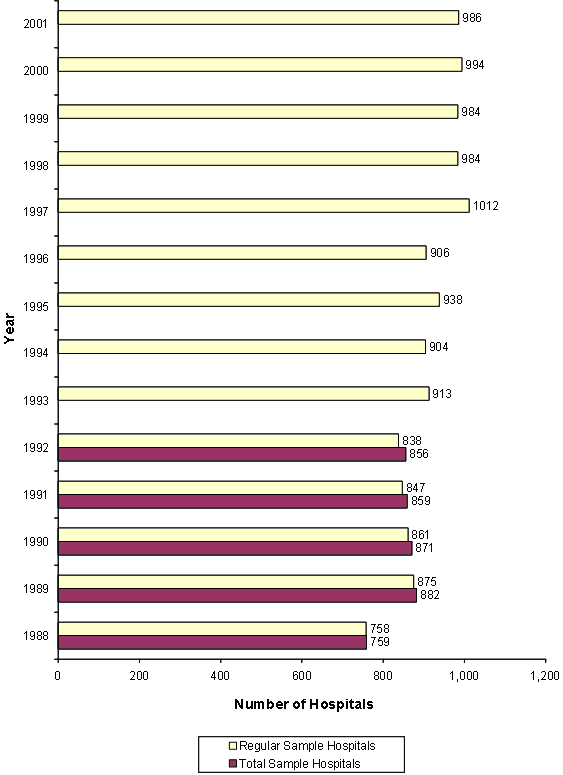
Figure 6: Number of NIS Discharges, by Year (text version)
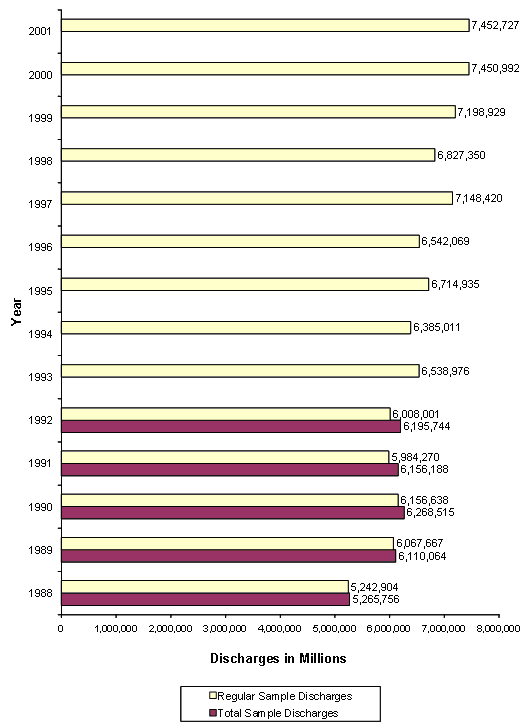
Figure 7: Number of NIS Discharges, Weighted, by Year (text version)

Figure 8 presents a summary of the 2001 NIS hospital sample by geographic region and the number of:
For example, in 2001 the Northeast region contained 668 hospitals in the universe. It also contained 625 hospitals in the frame, of which 136 hospitals were drawn for the sample. This was two more than the target sample size of 134 hospitals, resulting in a surplus of two hospitals over the target. The total sample exceeded the target by 23 hospitals, with a resulting sample of 20.5% of the total hospital universe. We sampled more than the target number of hospitals in each region because we rounded the target sample size for each stratum up to the next highest integer whenever it was not an integer.
Figure 9 summarizes the estimated U.S. population on July 1, 20012 by geographic region, and for each region shows:
For example, the estimated population of the Northeast region on July 1, 2001 was 53,950,802. The estimated population on July 1, 2001, of states in the Northeast region that were included in the 2001 NIS was 52,691,443. This represents 97.7% of the total Northeast region population. The percentage of estimated U.S. population included in states in the 2001 NIS was almost as high in the West (88.7%), but was lower in the South (81.0%). The three Midwest states added to the 2001 NIS have substantially increased the percentage of the Midwest population represented, from 45.0% in the 2000 NIS to 70.8% in the 2001 NIS. Overall, the states in the 2001 NIS include an estimated 83.6% of the entire U.S population.
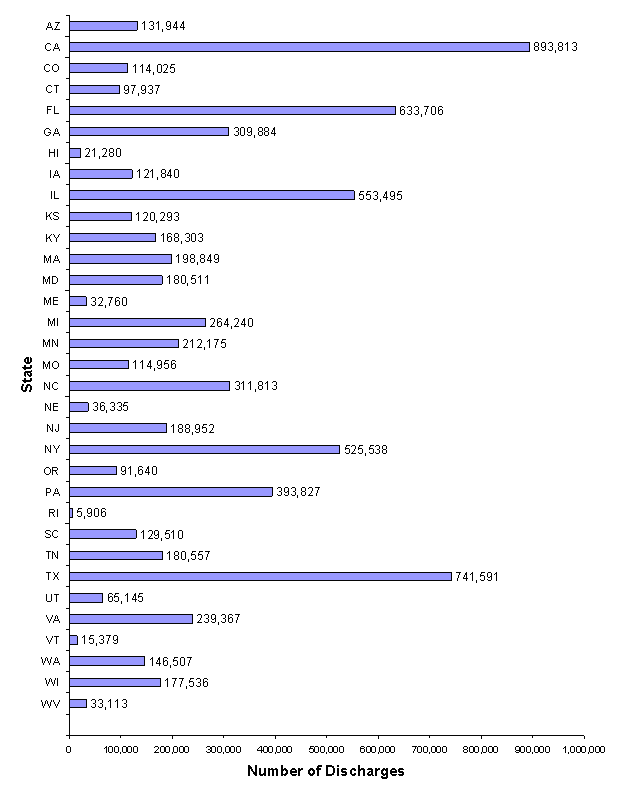
Figure 10 shows the number of discharges in the 2001 sample for each state. The number of sampled discharges in each state ranges from 5,906 discharges from Rhode Island to 893,813 from California.
Figure 8: Number of Hospitals in 2001 Universe, Frame, Target, Sample, and Surplus, by Region (text version)
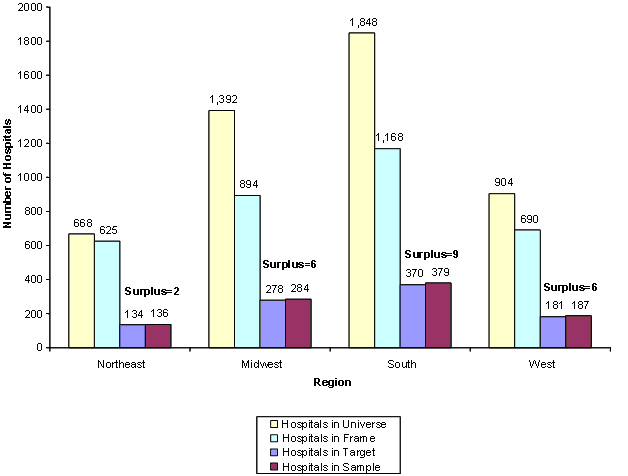
Figure 9: Percentage of U.S. Population in 2001 NIS States, by Region (text version)
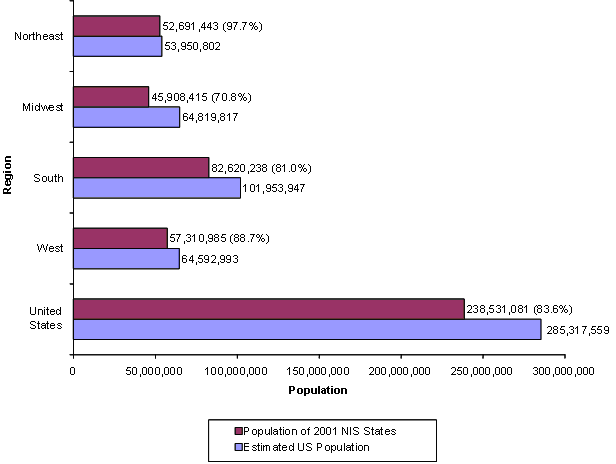
Figure 10: Number of Discharges in the 2001 Sample, by State (text version)
To obtain nationwide estimates, we developed discharge weights using the AHA universe as the standard. These were developed separately for hospital- and discharge-level analyses. Hospital-level weights were developed to extrapolate NIS sample hospitals to the hospital universe. Similarly, discharge-level weights were developed to extrapolate NIS sample discharges to the discharge universe.
Hospital weights to the universe were calculated by post-stratification. For each year, hospitals were stratified on the same variables that were used for sampling: geographic region, urban/rural location, teaching status, bed size, and control. The strata that were collapsed for sampling were also collapsed for sample weight calculations. Within each stratum s, each NIS sample hospital's universe weight was calculated as:
Ws(universe) = Ns(universe) ÷ Ns(sample)
where Ws(universe) was the hospital universe weight, and Ns(universe) and Ns(sample) were the number of community hospitals within stratum s in the universe and sample, respectively. Thus, each hospital's universe weight (HOSPWT) is equal to the number of universe hospitals it represents during that year. Because 20% of the hospitals in each stratum were sampled when possible, the hospital weights are usually near five.
The calculations for discharge-level sampling weights were similar to the calculations of hospital-level sampling weights. The discharge weights usually are constant for all discharges within a stratum. The only exceptions are for strata with sample hospitals that, according to the AHA files, were open for the entire year but contributed less than their full year of data to the NIS. For those hospitals, we adjusted the number of observed discharges by a factor of 4 ÷ Q, where Q was the number of calendar quarters for which the hospital contributed discharges to the NIS. For example, when a sample hospital contributed only two quarters of discharge data to the NIS, the adjusted number of discharges was double the observed number. This adjustment was done only for weighting purposes. The NIS dataset includes only the actual (unadjusted) number of observed discharges.
With that minor adjustment, each discharge weight is essentially equal to the number of AHA universe discharges that each sampled discharge represents in its stratum. This calculation was possible because the number of total discharges was available for every hospital in the universe from the AHA files. Each universe hospital's AHA discharge total was calculated as the sum of newborns and hospital discharges.
Discharge weights to the universe were calculated by post-stratification. Hospitals were stratified just as they were for universe hospital weight calculations. Within stratum s, for hospital i, each NIS sample discharge's universe weight was calculated as:
DWis(universe) = [DNs(universe) ÷ ADNs(sample)] * (4 ÷ Qi)
where DWis(universe) was the discharge weight; DNs(universe) was the number of discharges from community hospitals in the universe within stratum s; ADNs(sample) was the number of adjusted discharges from sample hospitals selected for the NIS; and Qi was the number of quarters of discharge data contributed by hospital i to the NIS (usually Qi = 4). Thus, each discharge's weight (DISCWT) is equal to the number of universe discharges it represents in stratum s during that year. Since all discharges from 20% of the hospitals in each stratum were sampled when possible, the discharge weights are usually near five.
To produce nationwide estimates, use one of the following discharge weights to extrapolate discharges in the NIS Core file to the discharges from all U.S. community, non-rehabilitation hospitals. When using one of the 10% subsample files, use the subsample discharge weight (the discharge weight multiplied by 10). When using the hospital weights with the subsample files, there is no need to multiply the hospital weights because all hospitals will be represented in the subsample files, thus the same hospital weight (HOSPWT) can be used for the full NIS and for the subsample files.
| NIS Year | Name of Discharge Weight on the Core File to Use for Creating Nationwide Estimates | Name of Discharge Weight on the 10% Subsample File to Use for Creating Nationwide Estimates |
|---|---|---|
| 2001 |
|
|
| 2000 |
|
|
| 1998-1999 |
|
|
| 1988-1997 |
|
|
Missing data values can compromise the quality of estimates. If the outcome for discharges with missing values is different from the outcome for discharges with valid values, then sample estimates for that outcome will be biased and will not accurately represent the discharge population. There are several techniques available to help overcome this bias. One strategy is to use imputation to replace missing values with acceptable values. Another strategy is to use sample weight adjustments to compensate for missing values3. Such data preparation and adjustment is outside the scope of this report. However, if necessary, it should be done before analyzing data with statistical procedures.
On the other hand, if the cases with and without missing values are assumed to be similar with respect to their outcomes, then no adjustment may be necessary for estimates of means and rates because the means and rates based on nonmissing cases would be representative of the means and rates of missing cases. However, some adjustment may still be necessary for the estimates of totals. Sums (of non-negative variables) would tend to be underestimated in the presence of missing values of the variable for which the total is estimated because the cases with missing values would be omitted from the calculations.
It may be important for researchers to calculate a measure of precision for some estimates based on the NIS sample data. Variance estimates must take into account both the sampling design and the form of the statistic. The sampling design was a stratified, single-stage cluster sample. A stratified random sample of hospitals (clusters) was drawn and then all discharges were included from each selected hospital.
If hospitals inside the frame are similar to hospitals outside the frame, the sample hospitals can be treated as if they were randomly selected from the entire universe of hospitals within each stratum. Standard formulas for a stratified, single-stage cluster sample without replacement could be used to calculate statistics and their variances in most applications.
A multitude of statistics can be estimated from the NIS data. Several computer programs are listed below that calculate statistics and their variances from sample survey data. Some of these programs use general methods of variance calculations (e.g., the jackknife and balanced half-sample replications) that take into account the sampling design. However, it may be desirable to calculate variances using formulas specifically developed for some statistics.
These variance calculations are based on finite-sample theory, which is an appropriate method for obtaining cross-sectional, nationwide estimates of outcomes. According to finite-sample theory, the intent of the estimation process is to obtain estimates that are precise representations of the nationwide population at a specific point in time. In the context of the NIS, any estimates that attempt to accurately describe characteristics (such as expenditure and utilization patterns or hospital market factors) and interrelationships among characteristics of hospitals and discharges during a specific year from 1988 to 2001 should be governed by finite-sample theory.
Alternatively, in the study of hypothetical population outcomes not limited to a specific point in time, the concept of a "superpopulation" may be useful. Analysts may be less interested in specific characteristics from the finite population (and time period) from which the sample was drawn, than they are in hypothetical characteristics of a conceptual “superpopulation” from which any particular finite population in a given year might have been drawn. According to this superpopulation model, the nationwide population in a given year is only a snapshot in time of the possible interrelationships among hospital, market, and discharge characteristics. In a given year, all possible interactions between such characteristics may not have been observed, but analysts may wish to predict or simulate interrelationships that may occur in the future.
Under the finite-population model, the variances of estimates approach zero as the sampling fraction approaches one, since the population is defined at that point in time, and because the estimate is for a characteristic as it existed at the time of sampling. This is in contrast to the superpopulation model, which adopts a stochastic viewpoint rather than a deterministic viewpoint. That is, the nationwide population in a particular year is viewed as a random sample of some underlying superpopulation over time. Different methods are used for calculating variances under the two sample theories. The choice of an appropriate method for calculating variances for nationwide estimates depends on the type of measure and the intent of the estimation process.
The hospital weights are useful for producing hospital-level statistics for analyses that use the hospital as the unit of analysis, while the discharge weights are useful for producing discharge-level statistics for analyses that use the discharge as the unit of analysis. The discharge weights may be used to estimate nationwide population statistics.
In most cases, computer programs are readily available to perform these calculations. Several statistical programming packages allow weighted analyses4. For example, nearly all SAS (Statistical Analysis System) procedures incorporate weights. In addition, several statistical analysis programs have been developed that specifically calculate statistics and their standard errors from survey data. Version 8 of SAS contains procedures (PROC SURVEYMEANS and PROC SURVEYREG) for calculating statistics based on specific sampling designs. STATA and SUDAAN are two other common statistical software packages that do calculations for numerous statistics arising from the stratified, single-stage cluster sampling design. Examples of the use of SAS, SUDAAN and STATA to calculate variances in the NIS are presented in the special report: Calculating Nationwide Inpatient Sample Variances, 2001. This report is available on the 2001 NIS Documentation CD-ROM and on the HCUP User Support Website at www.hcup-us.ahrq.gov. For an excellent review of programs to calculate statistics from survey data, visit the following Website: http://www.hcp.med.harvard.edu/statistics/survey-soft/. ![]()
The NIS database includes a Hospital Weights file with variables required by these programs to calculate finite population statistics. In addition to the sample weights described earlier, hospital identifiers (Primary Sampling Units or PSUs), stratification variables, and stratum-specific totals for the numbers of discharges and hospitals are included so that finite-population corrections (FPCs) can be applied to variance estimates.
In addition to these subroutines, standard errors can be estimated by validation and cross-validation techniques. Given that a very large number of observations will be available for most analyses, it may be feasible to set aside a part of the data for validation purposes. Standard errors and confidence intervals can then be calculated from the validation data.
If the analytical file is too small to set aside a large validation sample, cross-validation techniques may be used. For example, tenfold cross-validation would split the data into ten equal-sized subsets. The estimation would take place in ten iterations. In each iteration, the outcome of interest is predicted for one-tenth of the observations by an estimate based on a model fit to the other nine-tenths of the observations. Unbiased estimates of error variance are then obtained by comparing the actual values to the predicted values obtained in this manner.
Finally, it should be noted that a large array of hospital-level variables are available for the entire universe of hospitals, including those outside the sampling frame. For instance, the variables from the AHA surveys and from the Medicare Cost Reports are available for nearly all hospitals. To the extent that hospital-level outcomes correlate with these variables, they may be used to sharpen regional and nationwide estimates.
As a simple example, each hospital's number of cesarean sections would be correlated with their total number of deliveries. The number of cesarean sections must be obtained from discharge data, but the number of deliveries is available from AHA data. Thus, if a regression model can be fit predicting cesarean sections from deliveries based on the NIS data, that regression model can then be used to obtain hospital-specific estimates of the number of cesarean sections for all hospitals in the universe.
Hospitals that continue in the NIS for multiple consecutive years are a subset of the hospitals in the NIS for any one of those years. Consequently, longitudinal analyses of hospital-level outcomes may be biased, if they are based on any subset of NIS hospitals limited to continuous NIS membership. In particular, such subsets would tend to contain fewer hospitals that opened, closed, split, merged, or changed strata. Further, the sample weights were developed as annual, cross-sectional weights rather than longitudinal weights. Therefore, different weights might be required, depending on the statistical methods employed by the analyst.
One approach to consider in hospital-level longitudinal analyses is to use repeated-measure models that allow hospitals to have missing values for some years. However, the data are not actually missing for some hospitals, such as those that closed during the study period. In any case, the analyses may be more efficient (e.g., produce more precise estimates) if they account for the potential correlation between repeated measures on the same hospital over time, yet incorporate data from all hospitals in the sample during the study period.
The two nonoverlapping 10% subsamples of discharges were drawn from the NIS file for each year for several reasons pertaining to data analysis. One reason for creating the subsamples was to reduce processing costs for selected studies that will not require the entire NIS. Another reason is that the two subsamples may be used to validate models and obtain unbiased estimates of standard errors. That is, one subsample may be used to estimate statistical models, and the other subsample may be used to test the fit of those models on new data. This is a very important analytical step, particularly in exploratory studies, where one runs the risk of fitting noise in the data.
For example, it is well known that the percentage of variance explained by a regression, R2, is generally overestimated by the data used to fit a model. The regression model could be estimated from the first subsample and then applied to the second subsample. The squared correlation between the actual and predicted value in the second subsample is an unbiased estimate of the model's true explanatory power when applied to new data.
This report has described the development and use of the NIS sample and weights, summarized the contents of the 2001 NIS, and highlighted important points to consider during data analysis. The five new states in the 2001 NIS have enhanced the nationwide representation of the sample, making this the most comprehensive NIS to date.